









Whilst the newer version of VMware NSX, NSX-T is gaining some traction in the wider community of late, it has yet to reach the level of business adoption that NSX Data Center (formally/affectionately known as NSX-v) has. There are still many, many organisations running NSX Data Center.
With that in mind, I wanted to post a series of articles performing a site failover and recovery of my NSX Data Center test lab.
This post is part 1 of a multipart series. Find the other parts here:
- Part 1: This part - Why and Getting Familiar
- Part 2: Bye-bye Site A!
- Part 3: Site A Back from the Dead!
- Part 4: Making Site A Primary Again
Overview
Why?
As can be seen below, an NSX Data Center installation requires several components to operate:
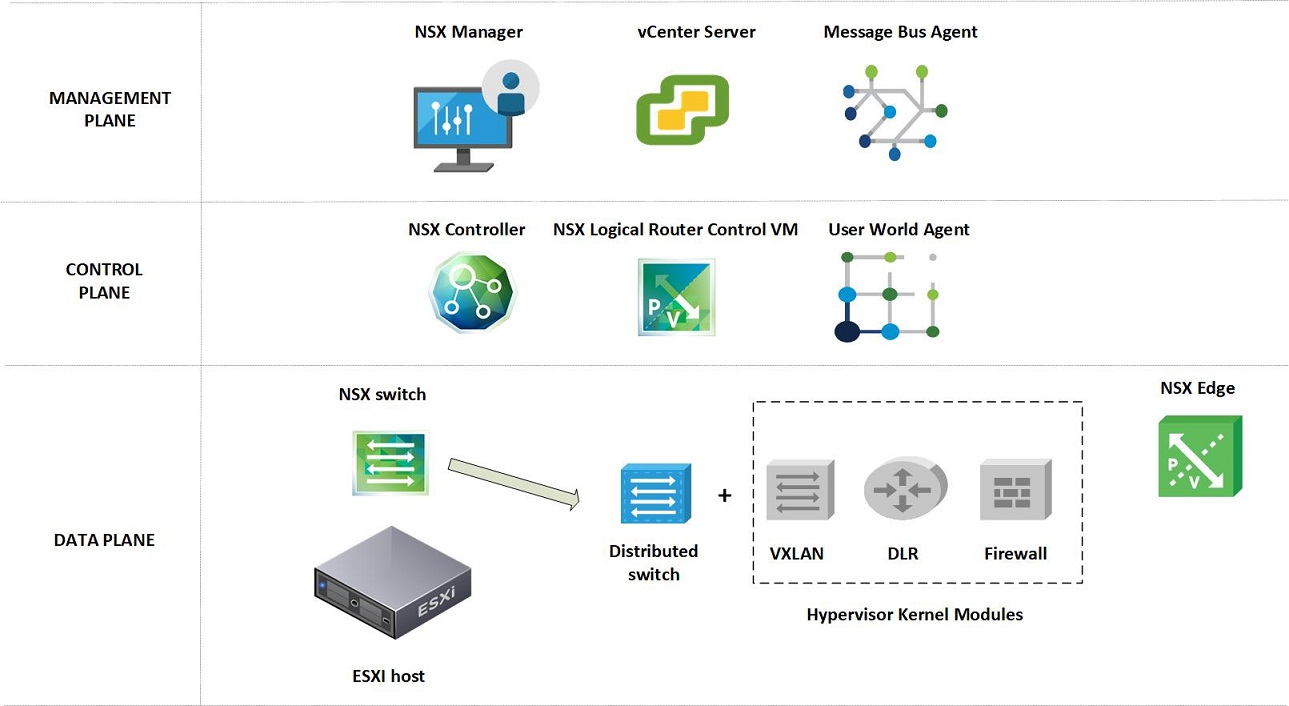
Working down from the top of the image -
Management Plane
These components consist of vCenter and NSX Manager. Typically these are “doubled up” - that is they are deployed on each site of an NSX for Data Center solution/environment.
Control Plane
These components consist of our NSX Controller cluster and our Universal Logical Distributed Router (UDLR) control VMs.
The control plane VMs can only exist on ONE SITE, typically the primary site. Because they can only exist on one site, in the event of loss of the site containing the control VMs, they must be recreated at a secondary site to reinstate the NSX control plane.
Data Plane
These components consist of the ESXi hosts and the NSX Edge (also known as Edge Service Gateway or ESG) VMs. Again, typically these are “doubled up” - that is they are deployed on each site of an NSX for Data Center solution/environment.
Types of Failover
Essentially there are two types of failover scenario:
Planned Failover
The primary site is going offline for an extended period of time.
For example a relocation of the site to a new building. Any service outages are known about ahead of time and can be planned for and mitigated as much as possible up front.
Unplanned Failover
The primary site is suddenly offline and will remain so for an extended period of time.
It is what it is. Pieces need picking up and any service outages need to be addressed as soon as possible.
Getting Familiar with the Lab
We will be performing failover in the following lab:
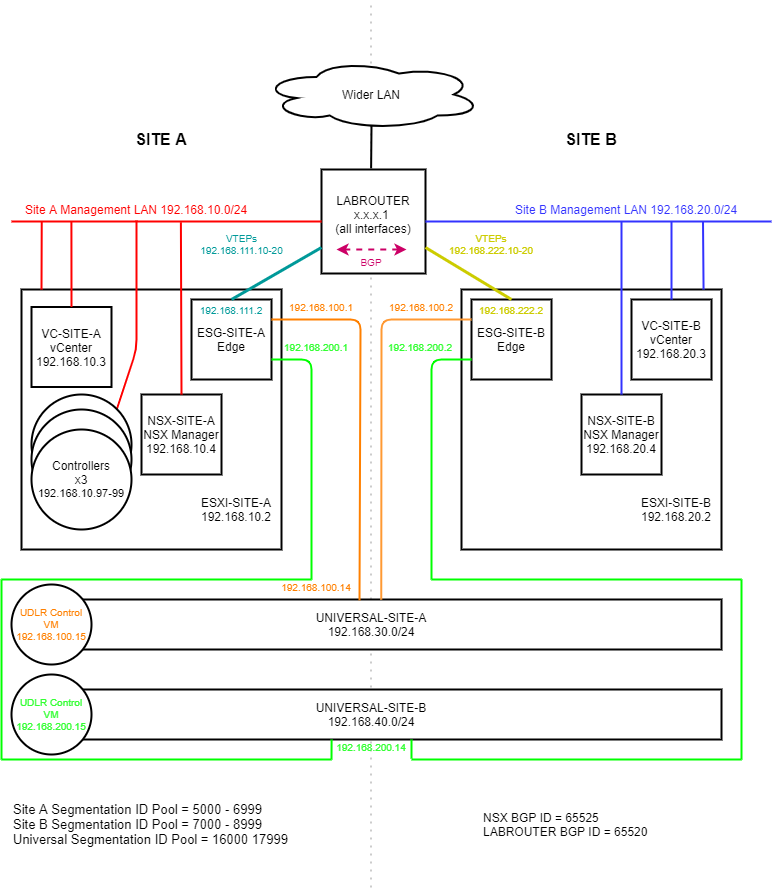 (Click image to zoom in)
(Click image to zoom in)
Lab Items Worthy of Note
- Two site model with vCenters and NSX Managers deployed at each site
- Site A is the primary site
- Site B is the secondary site
- Site A houses NSX controller cluster and the UDLR control VMs
- “UNIVERSAL-SITE-A” and “UNIVERSAL-SITE-B” represent the universal layer 2 VXLANs spanning both A and B sites
- VMs plugged in to “UNIVERSAL-SITE-A” use ESG-SITE-A as their preferred north/south egress/ingress point
- VMs plugged in to “UNIVERSAL-SITE-B” use ESG-SITE-B as their preferred north/south egress/ingress point
- BGP peering is used between UDLRs, ESGs and LABROUTER (a pfSense router) for dynamic routing
Failover Prerequisites
The following should ideally be configured / captured prior to a failover event:
- Ensure that Controller Disconnected Operation (CDO) mode is enabled on all NSX Managers in the environment
- Setup an IP Pool for the NSX Controllers on the secondary site
- UDLR configuration captured - including interfaces, ECMP status, static routes (if any) and BGP config
- Admin credentials for all ESGs, UDLR control VMs, NSX Managers and vCenters at both sites
Component Placement After a Failover
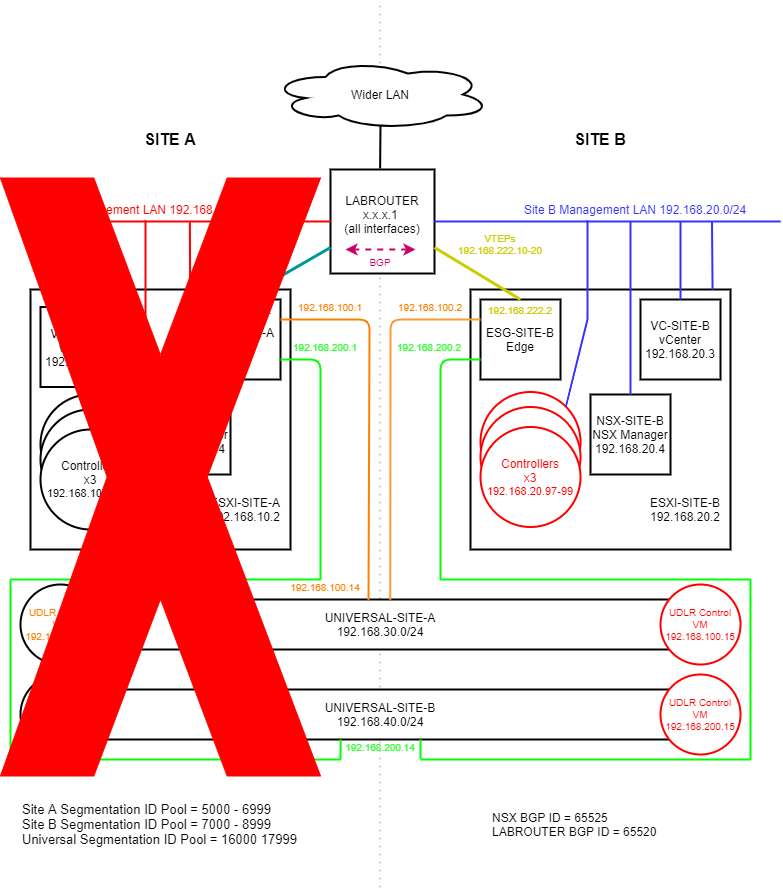 (Click image to zoom in)
(Click image to zoom in)
Following a failover of Site A to Site B, the following can be observed:
- NSX Controller cluster is rebuilt on Site B
- Universal Site A UDLR control VM is rebuilt on Site B
- Universal Site B UDLR control VM is rebuilt on Site B
Additionally, Site B NSX Manager promoted to primary. The rebuilt VMs are shown in red at Site B in the above diagram.
Conclusion and Wrap Up
That’ll do it for part one.
In this part we looked at failure scenarios, became familiar with our NSX test lab. We also looked at prerequisites to enable a smooth failover. Over the next couple of posts we will get into performing a primary site failover along with a failback once our failed site returns.
This was part 1 of a multipart series. Find the other parts here:
- Part 1: This part - Why and Getting Familiar
- Part 2: Bye-bye Site A!
- Part 3: Site A Back from the Dead!
- Part 4: Making Site A Primary Again
Look out for future parts coming soon!
-Chris